Deuxième article de notre série destinée à vous présenter les nouveautés de notre reverse-proxy HTTP. Après le pare-feu applicatif, nous vous présentons le cache HTTP frontal que nous avons intégré à notre infrastructure.

Un cache HTTP, qu’est-ce que c’est ?
Un graphique vaut mieux qu’un long discours
Nous avons testé les performances de notre cache fraîchement intégré à notre proxy sur notre blog, servi par une application WordPress. Le résultat obtenu nous laisse à penser que cette fonctionnalité va vous plaire.
Le nombre de requêtes servies par seconde augmente considérablement lorsqu’on active notre cache, passant de 15 req/s à 2604 req/s, soit 173 fois plus de requêtes servies sur une même durée. Le temps mis pour obtenir la réponse à une requête baisse d’autant, passant de 63.65ms à 0.38ms en moyenne. Intéressant, et très simple à activer !
Nous avons réalisé ce benchmark avec ApacheBench en faisant des requêtes vers la page d’accueil de ce blog. Nous avons exécuté chaque tir1) quatre fois pour chaque configuration, avec et sans cache, avant de faire la moyenne des résultats obtenus. Ce blog est hébergé sur un serveur dédié, les différences de performances mesurées sur un serveur mutualisé seront du même ordre. Vous pouvez d’ailleurs faire vos propres tests en vous connectant en SSH à votre serveur, et en exécutant la commande ab avec les mêmes options sur une page de votre site.
Fonctionnement d’un cache
Le cache désigne un système de stockage temporaire de données dans le but d’en accélérer le traitement ultérieur. Un cache HTTP s’occupe de stocker temporairement des documents web comme les pages HTML, les documents CSS, les images, etc. Ce mécanisme est principalement utilisé pour diminuer la latence induite par le serveur lorsqu’il doit servir une page et/ou réduire sa charge de travail.
Lorsqu’un client demande une page à un serveur web, ce dernier va générer une page et l’envoyer sur le réseau. Le cache intercepte la réponse à ce moment, et la stocke dans sa mémoire locale avant de la servir au client.
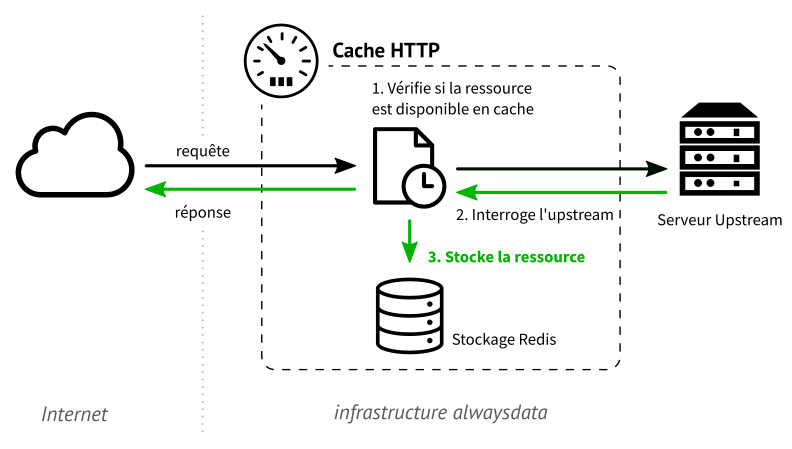
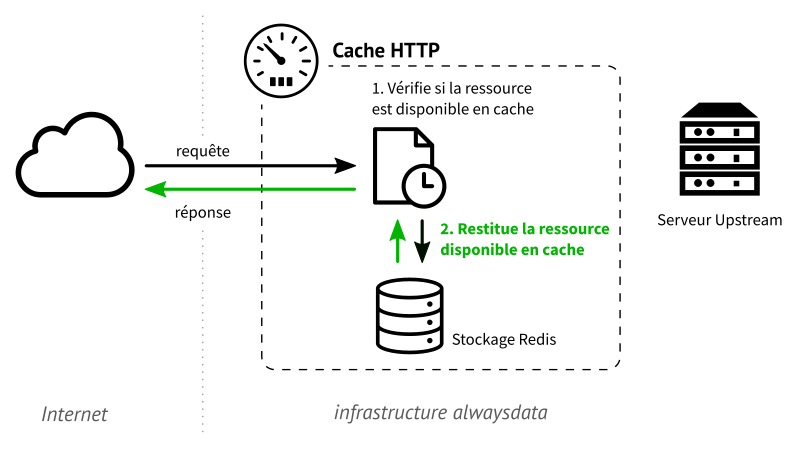
Lorsqu’une requête pour la même page est émise par un client, elle sera directement servie par le cache qui détient désormais une copie de la ressource demandée. Le serveur web ne sera plus interrogé.
Utiliser le cache chez alwaysdata
Vous pouvez activer le cache frontal pour chaque site individuellement en vous rendant simplement dans Sites → Modification → Cache, puis en cochant la case Activer le cache.
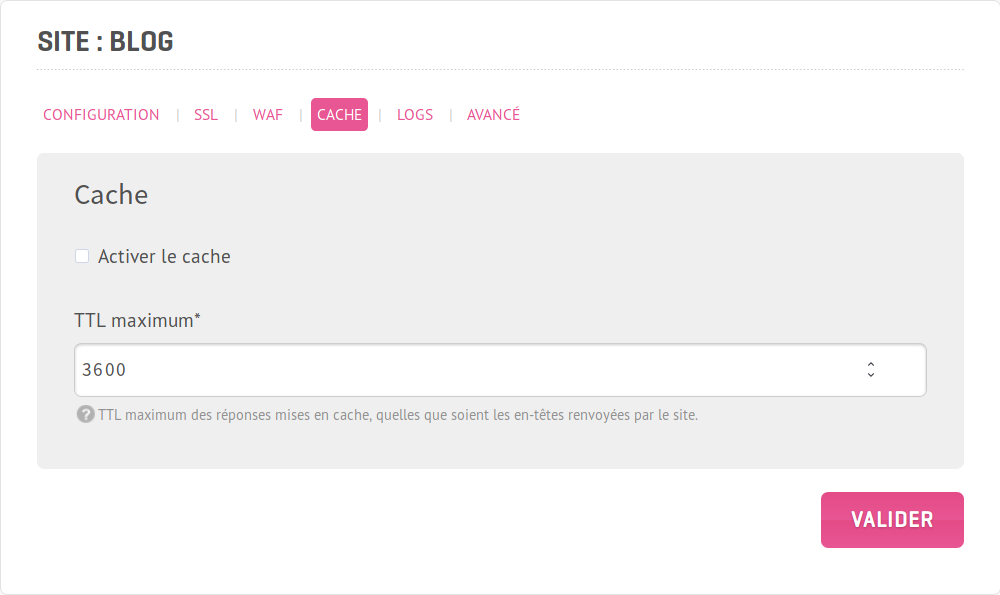
Il vous faudra régler le TTL pour les pages issues de ce site. Le TTL définit la durée pendant laquelle le cache peut servir une page. Sa valeur doit être sélectionnée avec soin. S’il est bon de choisir un TTL élevé pour un site dont le contenu n’est pas souvent mis à jour ; il sera en revanche judicieux d’abaisser cette valeur dans le cas d’un site dont le contenu change très régulièrement, comme un site de news. Dans ce dernier cas, si le TTL reste élevé, le visiteur peut se retrouver avec une version périmée de la page demandée.
Prenons l’exemple de ce blog. Nous souhaitons nous assurer qu’un visiteur se retrouve avec une version relativement fraîche de la page d’accueil. Lorsque nous ajoutons un article, la page d’accueil cachée auparavant sera périmée. Nous allons donc préférer une valeur de TTL comprise entre 5 et 10 secondes afin de bénéficier des hausses de performances sans risquer de servir la page cachée pendant une durée trop longue.
Cette fonctionnalité est considérée comme en bêta test et susceptible d’évoluer encore.
Cette fonctionnalité est dépendante de la capacité de votre application à autoriser les pages générées à être cachées. Si cette dernière ne l’autorise pas explicitement, il y a un risque que notre proxy ne puisse pas cacher les ressources qui sont servies par elle.
L’implémentation
Nous avons choisi d’écrire en Python2) un module intégrant les spécifications du standard exposées dans la RFC 7234. Le stockage des ressources cachées, quant à lui, est confié à un serveur Redis local permettant l’optimisation de la mémoire utilisée avec très peu d’efforts.
En plus des spécifications liées à la RFC, nous avons implémenté le verbe HTTP PURGE. Cette méthode offre la possibilité de supprimer une entrée dans le cache par le client juste en l’appelant sur son URL. Ceci peut être utile lorsque vous cherchez à forcer le rafraîchissement d’une page mise en cache.
Après la performance, la journalisation ! Dans le prochain et dernier billet de cette série, nous vous présenterons notre système de personnalisation des lignes de logs générées par vos serveurs web. Vous allez désormais pouvoir les formater selon vos besoins.
Super mais il y a beaucoup de questions pour un noob comme moi. Du genre, est-ce qu’il ne vaut pas mieux privilégier une extension de cache pour WordPress qui sera plus paramétrable ? Est-ce que les deux sont compatibles ?
Le cache applicatif et le cache HTTP sont cumulables. Le premier est plus souple (permet par exemple de cacher des morceaux de page ou des requêtes SQL), le second est plus performant (l’application n’est même pas sollicitée).
En l’occurrence pour WordPress, par défaut les pages renvoyées ne sont pas cachables. Il vous faudra donc un plugin pour que les pages deviennent cachables… et en général ces sont des plugins de cache applicatif qui permettent cela, d’où la confusion. Par exemple, pour ce blog nous avons utilisé W3 Total Cache.
Hum, si je comprends bien, si le site est sous WP, inutile d’activer le cache HTTP.
Oui, du moins sans ajouter de plugin.
Merci pour cette super fonctionnalité ! Est-elle déjà active sur les (nos) serveurs dédiés ?
Est-ce qu’il y a plus de documentation sur une autre page ?
Quelles sont les en-têtes à mettre pour passer dans le cache ? (genre Cache-Control : max-age=3600, public ?)
Comment voir dans les en-têtes si le fichier vient du cache ?
Merci
Oui, c’est actif sur les serveurs dédiés également. On n’a pas davantage de documentation, mais on répond aux questions ici ou via le support ;-)
Concernant les en-têtes, on suit les RFC, rien de particulier à alwaysdata. Par défaut (donc sans en-tête particulière), une page est cachable. Évidemment, on peut utiliser Cache-Control pour influer sur le cache, donc “Cache-Control : max-age=3600, public” fera ce que c’est censé faire.
Pour savoir si une réponse provient du cache, c’est l’en-tête “Age”.
Super content de pouvoir utiliser un système avec de telles performances sans avoir à faire appel des prestataires à modèle centralisé comme CloudFlare. Merci alwaysdata :)
Juste par curiosité, quels sont les réglages que vous avez utilisé pour le cache dans W3 Total Cache sur ce blog ? Et merci pour ces belles nouveautés !
L’important est d’activer le Browser Cache, ce qui permet alors à notre cache HTTP de fonctionner (car les réponses renvoyées par WordPress auront les bonnes en-têtes).
Bonjour,
Existera-t-il par hasard une méthode pour flusher le cache globalement ou par url ? Via l’API ?
Ce serait le TOP !
Thomas : vous voulez dire flusher globalement pour tout un site voire tout un compte ? Pour le moment ce n’est pas possible, seul le flush par URL est supporté.
@Cyril oui je parlais par site, mais j’ai lu un peu trop vite et je vois que PURGE est implémenté, c’est top !
@Cyril : « Oui, du moins sans ajouter de plugin. »
C’est à dire ? En gros si j’ai WP Super cache (qui est applicatif il me semble), il est inutile d’activer le cache HTTP, c’est cela ?
Merci :)
Non, ce que je voulais dire c’est que si vous n’avez aucun plugin de cache pour WordPress, alors activer le cache HTTP ne servira à rien (parce que par défaut, sans plugin, WordPress refuse de se laisser cacher).
En revanche, si vous avez un plugin de cache qui « gère le cache HTTP » (qui permet aux pages WordPress de se laisser cacher), alors là il est très utile d’activer le cache HTTP dans l’administration alwaysdata.